- DevOps Dispatch
- Posts
- Ensuring Business Continuity: A Comprehensive Guide to Multi-Region Active-Passive Disaster Recovery on AWS
Ensuring Business Continuity: A Comprehensive Guide to Multi-Region Active-Passive Disaster Recovery on AWS
Manan Goradiya
April 20, 2025
Is your business prepared for the unexpected? In today’s fast-paced digital world, even a brief service outage can cost you more than just money — it can impact your reputation. Enter AWS Active-Passive Disaster Recovery (DR), the perfect balance between cost-efficiency and readiness. This blog breaks down the essentials of Active-Passive DR, from its architecture to real-world benefits, and shows you how to keep your business running smoothly, even in the face of adversity. Ready to safeguard your operations? Let’s dive in!

What is Active-Passive Disaster Recovery?
Active-Passive Disaster Recovery (DR) is a type of disaster recovery strategy where two environments (primary and secondary) are used to ensure business continuity.
Active Environment: In this setup, the primary site or region is actively running and handling production workloads. The system is fully operational, and all resources are in use.
Passive Environment: The secondary site or region remains idle or on standby. It is synchronized with the primary environment, but it does not handle live traffic or workloads unless a failure occurs.

Major Infrastructure Components
+------------------------+--------------------------+
| Major Infra Components |
+------------------------+--------------------------+
| Cloudflare | CodeBuild & CodePipeline |
| WAF | ECR |
| CloudFront | Secrets Manager |
| S3 | ElastiCache - Redis |
| LoadBalancer | CloudWatch |
| EKS with EC2 Nodes | AWS Backup |
| Karpenter | Inspector |
| RDS | GuardDuty |
| OpenSearch | EFS |
+------------------------+--------------------------+3. Infrastructure Components considered for DR
+------------------------+
| DR Components |
+------------------------+
| RDS |
| OpenSearch |
| ElastiCache Redis |
| EFS |
| Kubernetes Deployments |
| S3 |
+------------------------+4. Replication Management from Primary region to Secondary region
RDS — To ensure database availability, configure a Multi-AZ RDS setup in the primary region, with a Read Replica in the secondary region.
OpenSearch —Configuring OpenSearch domains in both the primary and secondary regions, enabling cross-cluster replication. This ensures that any changes to the OpenSearch data in the primary region are replicated in real-time to the secondary region.
Elasticache Redis — For caching, leverage AWS ElastiCache Global Datastore to replicate data between the primary and secondary regions. This solution enables near real-time data replication.
EFS — In order to maintain data consistency across regions, configure cross-region EFS replication. This ensures that all file data from the EFS in the primary region is automatically replicated to the secondary region, providing seamless access to files and critical applications during a disaster recovery scenario.
Kubernetes deployments — For Kubernetes, initially set the deployments in the secondary region to have zero replicas. During a disaster recovery event, these deployments are scaled up to handle production traffic, ensuring that the applications remain available and responsive without manual intervention.
S3 — Cross-region replication for S3 between the primary and secondary regions to ensure that all data is continuously synchronized.
5. Key AWS Services Powering My Disaster Recovery Solution
+ - - - - - - - - - -+
| EventBridge |
| Lambda Functions |
| GlobalAccelerator |
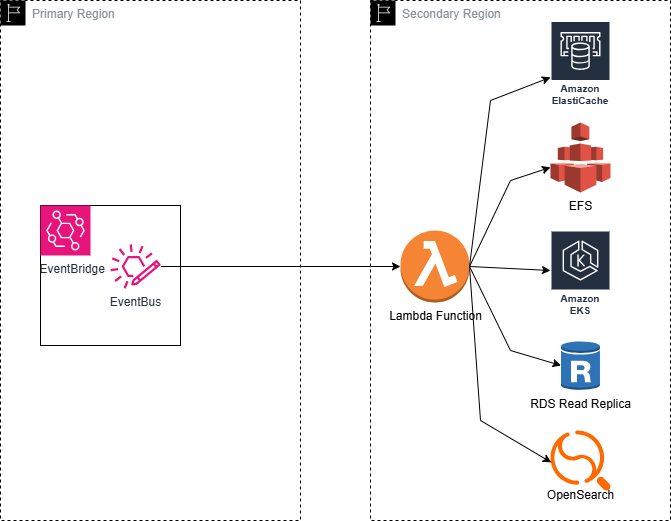
+ - - - - - - - - - -+EventBridge —Setup EventBridge event rules to monitor and respond to outage events across AWS services.
Lambda Functions — Configured Lambda functions to automate key DR actions, such as promoting the RDS read replica in the secondary region, activating the ElastiCache cluster in the secondary region, stopping EFS replication, scaling Kubernetes deployments, and updating traffic routing in Global Accelerator.
6. DR Solution Outcomes: Rapid Recovery and Zero Data Loss
With this disaster recovery solution in place, the Recovery Time Objective (RTO) was successfully reduced to 15 minutes, ensuring rapid failover to the secondary region. Additionally, the Recovery Point Objective (RPO) was minimized to 0 minutes, ensuring zero data loss during the failover process. This setup provides near-instantaneous recovery and guarantees that business operations continue smoothly without data interruptions, even during an outage.
7. At first glance, you might wonder: Why not use Route 53 failover policy for disaster recovery?
The answer lies in the specific requirements of this solution. The need was to implement an Active-Passive DR architecture while leveraging domain management in Cloudflare. Since the domains are managed in Cloudflare, it wasn’t possible to utilize Route 53’s failover policy for handling failovers. Instead, the solution had to align with the tools and configurations already in place to ensure seamless integration and reliability.
This highlights the importance of tailoring a DR strategy to fit the unique needs and constraints of the infrastructure.